第13章 多元统计方法简介
1. 聚类分析 (Cluster Analysis)
核心思想
聚类分析是一种无监督学习(Unsupervised Learning),事先不知道样本的分类标签,根据数据特征的相似性(“物以类聚”)将样本划分为不同类别。

关键统计量
-
样品间的距离:用于度量样本(Sample)之间的相似性,常用欧氏距离、绝对值距离、明氏距离。
-
变量间的相似系数:用于度量指标(Variable)之间的相似性,如夹角余弦、相关系数。
主要方法
系统聚类法 (Hierarchical Clustering)
-
基本步骤:起初将 \(n\) 个样品看作 \(n\) 类,计算两两距离,逐步合并距离最近的两类,重复此过程直到所有样品归为一类。
-
类间距离定义:
-
最短距离法:类间距离 = 两类中最近样品的距离。
-
最长距离法:类间距离 = 两类中最远样品的距离。
-
重心法:各类重心(均值)之间的距离。
-
-
可视化:树状图 (Dendrogram) 是展示系统聚类合并过程最直观的工具。
例题:系统聚类的可视化
对于一个系统聚类过程,以下哪种图形化结果可以最直观地展示整个聚类的合并过程与层次结构?
A. 散点图矩阵
B. 平行坐标图
C. 树状图(Dendrogram)
D. 碎石图(Scree Plot)
正确答案:C
解析:树状图以树形结构展示样本或类的逐级合并过程及距离,是系统聚类的标准可视化工具。
动态聚类法 (K-means Clustering)
-
核心逻辑:
- 初始化:必须预先指定聚类数量 \(k\)。
- 分配:将每个样品分配给最近的均值(质心)。
- 迭代:更新质心并重新分配,直到收敛。
-
应用场景:市场细分、客户分类等无标签数据探索。
K-means算法
关于K-means算法的描述,以下哪一项是不正确的?
A.聚类的最终结果与初始质心的选择无关
B.算法的目标是最小化簇内误差平方和(SSE)
C.该算法对于离群值(outliers)比较敏感
D.算法倾向于发现大小相似的球状簇
正确答案: A
答案解释: K-Means对初始质心敏感,不同初始化可能导致不同局部最优解,故结果可能不同。A项错误。
例题:K-means 算法特征
关于K-means聚类算法,以下描述正确的是:
A. 它是一种分层、聚合式的聚类方法
B. 它要求事先确定一个距离阈值来停止合并
C. 它需要研究人员预先指定聚类的数量
D. 最终的聚类结果与初始类中心的随机选择无关
正确答案:C
解析:K-means必须预先指定簇数 \(k\),这是其基本输入参数。A描述的是系统聚类。
例题:聚类分析的应用场景
以下哪种数据类型或研究场景特别适合使用聚类分析?
A. 检验两种药物疗效的差异
B. 分析一个自变量对因变量的影响
C. 根据客户的特征(如消费金额、频率、品类)进行市场细分
D. 建立风险预测评分模型
正确答案:C
解析:聚类分析用于无监督分组(无标签),适用于探索性市场细分。其他选项均为有监督分析或假设检验。
2. 判别分析 (Discriminant Analysis)
核心思想
判别分析是一种有监督学习(Supervised Learning)。根据已知分类的训练样本建立判别函数(规则),对未知分类的新样本进行归类。
例题:判别分析的定义
判别分析的核心思想是:
A. 根据某些类别已知的训练样本建立判别函数;再将待判个体的相应变量值代入此判别函数,根据所得函数值判断该对象应该归入的类别。
B. 根据样本数据的内在判别性,将样本自动划分为若干个未知的类别,使得同一类别内的样本尽可能相似,不同类别间的样本尽可能不同。
C. 通过降维技术,将多个判别变量转化为少数几个不相关的综合变量,并尽可能保留原始变量的信息。
D. 建立因变量与自变量之间的判别方程,根据自变量的取值预测因变量的数值。
正确答案:A
解析:判别分析需利用“已知分类的数据”建立规则,再对“未知分类”样本进行预测。B是聚类分析,C是主成分分析。
常见判别准则
Fisher 判别 (Fisher Discriminant Analysis)
- 原理:投影降维。寻找一个投影方向,使得组间差异最大化 (\(S_b\)),同时组内差异最小化 (\(S_w\))。
- 目的:让不同类别的点尽可能分离,同类别的点尽可能聚集(最大化信噪比)。
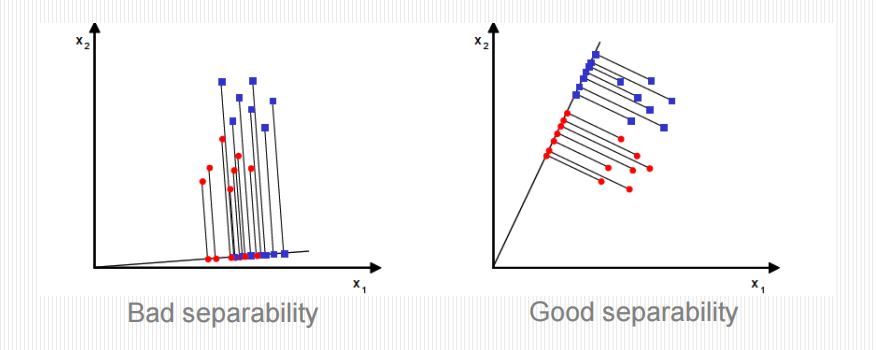
例题:Fisher 判别的目标
Fisher线性判别分析旨在找到一个线性组合,使得:
A. 组间差异最大化,同时组内差异最小化
B. 每个组内的方差最大化
C. 原始变量的总方差最大化
D. 潜在因子的数量最小化
正确答案:A
解析:Fisher判别准则为最大化组间离差与组内离差之比。
Bayes 判别 (Bayes Discriminant Analysis)
-
原理:引入先验概率,利用贝叶斯公式计算后验概率。
-
准则:将样本归入后验概率最大的一类,或使错判损失最小。
例题:Bayes 判别的特点
关于Bayes判别分析,下列说法正确的是:
A. 它不考虑不同类别的先验概率
B. 它以错判总平均损失最小或后验概率最大为判别准则
C. 它要求所有预测变量必须是连续的
D. 它与Fisher判别分析在所有情况下都是等价的
正确答案:B
解析:Bayes判别基于后验概率,核心目标是最小化期望误判损失。
距离判别法
基本思想是首先根据已知分类的数据(训练样本)分别计算各类的重心。对于任意给定的一个新样品,若它与第k类重心的距离最近,则该样品归属于第k类。
逐步判别法
基本思想是尽可能选择对判别有意义的自变量纳入方程,该判别方法和逐步回归思想类似,采用“有进有出”的规则逐步引入变量,直到判别函数中所有的变量都有统计学意义,判别过程停止。
Logistic回归判别法
基本思想是根据观察指标建立因变量Y和自变量X的logistic回归方程,并根据估计概率进行判别归类。对于两类判别问题,依据估计的p值和0.5的比较进行二分类,p=0.5暂不归类。
判别效果的验证
(1)组内回代
使用已建立的判别公式对训练样本进行判别分类。如果分类结果与原分类符合程度高,则组内回代效果好。
(2)组外考核
使用训练样本以外的其他样本(称为组外考核样本)进行判别。有时不容易得到组外考核样本,就将原样本一分为二,一部分作为训练样本,另一部分则作为组外考核样本,此即所谓的交叉验证。常用的交叉验证法包括K折交叉验证和留一法。
3. 主成分分析 (PCA)
核心思想
-
目的:数据降维。将多个相关的原变量通过线性变换,组合成少数几个互不相关(相互独立)的综合变量(主成分),同时尽可能保留原始信息。
-
几何意义:对坐标轴进行旋转,找到数据方差最大的方向。
关键性质
-
主成分是原变量的线性组合。
-
各主成分之间互不相关 (正交)。
-
主成分按方差(特征根)大小排序,反映信息量的多少。
分析步骤
-
标准化:常用 Z-score 标准化(标准正态变换),消除量纲影响。
-
选取主成分:依据累计方差贡献率(通常 >80%)或碎石图。
例题:PCA 的性质辨析
下列关于主成分分析的表述不正确的是:
A. 目的是寻找少数几个主成分代表原来的多个指标
B. 所确定的几个主成分之间是高度相关的
C. 所确定的几个主成分之间是互不相关的
D. 若相关矩阵是单位矩阵,说明资料不宜做主成分分析
E. 各主成分是原来变量的线性组合
正确答案:B
解析:PCA 的核心特征之一就是生成的各个主成分之间是相互独立(互不相关/正交)的。因此 B 说法错误。
例题:PCA 的标准化
在进行主成分分析时,需对原始变量进行标准化处理,常用的标准化方法是:
A. 将原始变量向0到1之间转换
B. 将原始变量向-1到1之间转换
C. 对数转换
D. 标准正态转换
E. 减去均值的中心化转换
正确答案:D
解析:PCA通常使用Z-score标准化(即标准正态转换),使变量均值为0、标准差为1。
例题:PCA 的应用选择
某研究人员希望通过少数几个综合指标来代替多个相关的原始经济指标,同时尽可能多地保留原始变量的信息。最适合的分析方法是:
A. 主成分分析
B. 因子分析
C. Fisher判别分析
D. 聚类分析
正确答案:A
解析:主成分分析的核心目标就是“提取指标共性特征,实现数据降维”,用少数综合变量概括信息。
例题:多选题——主成分的特征
主成分分析(PCA)通过线性变换生成新的变量(主成分),关于主成分,说法正确的是:(多选)
A. 彼此高度相关
B. 与原始变量的数量相同,且都必须保留
C. 尽可能多地解释原始变量之间的协方差
D. 彼此线性无关(正交),并按解释方差的大小排序
E. 选择保留多少个主成分通常依据的原则是保留的主成分的累计方差贡献率达到某个阈值(如80%)
正确答案:D, E
4. 因子分析 (Factor Analysis)
核心思想
-
目的:寻找支配众多可测变量的少数几个潜在公因子 (Latent Factors),解释变量间的相关性结构。
-
模型: $$ x_i = l_{i1}F_1 + l_{i2}F_2 + \dots + l_{ik}F_k + \delta_i $$
- \(F_j\) (公因子):影响所有变量的共同因素。
- \(\delta_i\) (特殊因子/个性因子):只影响第 \(i\) 个变量,包含测量误差。
关键概念
- 因子负荷 (\(l_{ij}\)):变量 \(x_i\) 与公因子 \(F_j\) 的相关系数,反映 \(F_j\) 对 \(x_i\) 的重要性。
- 因子旋转:使因子负荷向 0 和 1 两极分化,提高因子的可解释性。变异最大旋转,指各变量在各主因子上的负载最大限度地分散,各负荷通过除以所对变量的共性方差来校正,此方法可保持各主因子间互不相关;斜交旋转,该方法放弃了限制主因子间的相关性,使各因子尽量通过各簇的中心。
例题:因子负荷的含义
关于因子负荷的解释,正确的说法是:
A. 实际上是 \(x_i\) 和 \(F_j\) 的相关系数
B. 取值越大,\(x_i\) 和 \(F_j\) 的关系越密切
C. 取值范围在0-1之间
D. 因子负荷一定大于0
E. 各变量 \(x_i\) 在某一主成分 \(C_j\) 上的因子负荷的平方和=1
正确答案:A
解析:在标准化变量和正交因子下,因子负荷 \(l_{ij} = \text{Corr}(x_i, F_j)\)。B虽直观但不够严谨(符号可负);C、D错误(可为负,绝对值可大于1在非标准化下);E描述的是主成分载荷性质。
例题:个性因子 \(\delta_i\)
关于因子分析中的个性因子 \(\delta_i\),错误的说法是:
A. 是服从正态分布的随机变量
B. 是指只影响一个观察变量的因子
C. 表示 \(k\) 个公因子之外的其它潜在因子对 \(x_i\) 的总影响
D. \(\delta_i\) 与 \(F_j\) 独立
E. \(\delta_i\) 之间彼此独立
正确答案:B
解析:根据定义,\(\delta_i\) 是个性因子,表示 \(k\) 个公因子之外其他潜在因子对 \(x_i\) 的总影响(C对),且满足正态分布假设(A对)和独立性假设(D、E对)。题目认定 B 为错误说法,可能是因为标准定义中 \(\delta_i\) 更多强调的是“残差”或“未能被公因子解释的部分”,包含测量误差,而不仅仅是“一个因子”。
PCA 与 因子分析的区别
-
PCA:是原变量的线性组合,无误差项,重在降维。
-
因子分析:假设存在潜在结构支配原变量,包含特殊因子 \(\delta_i\),重在解释相关性。
例题:PCA 与 FA 的区别
因子分析与主成分分析的一个关键区别在于:
A. 因子分析不能用于数据降维
B. 主成分分析需要对数据进行标准化,而因子分析不需要
C. 因子分析旨在识别解释变量间相关性的潜在结构(公共因子),而主成分分析旨在解释变量的总方差
D. 主成分分析的结果更具有可解释性
正确答案:C
例题:综合方法辨析
下列关于判别分析、主成分分析和因子分析三种分析方法的描述,不正确的是:
A. 判别分析属于监督学习方法...
B. 主成分分析和因子分析都可用于数据降维
C. 因子分析的模型中包含了特殊因子...
D. 主成分分析是将原始变量表示为各个主成分的线性组合
E. 在因子分析中,因子旋转的目的是使得因子更容易被解释
正确答案:D
解析:主成分分析是将主成分表示为原始变量的线性组合。因子分析才是将原始变量表示为因子的线性组合。D选项表述颠倒。
例题:潜在维度的应用
一家市场研究公司收集了消费者对某品牌多种属性的评分,希望了解这些评分背后是否存在一些共同的潜在维度(例如“产品质量”、“客户服务”)。最适合用于此目的的分析方法是:
A. 主成分分析
B. 因子分析
C. Bayes判别分析
D. Fisher判别分析
正确答案:B
解析:题目关键词是“寻找共同的潜在维度”或“构念”,这是因子分析的典型应用场景。
5.总结
-
K-means前提:必须预先指定聚类数量 \(k\)。
-
可视化工具:树状图 (Dendrogram) 是系统聚类的标配。
-
Fisher判别核心:组间差异最大化,组内差异最小化。
-
Bayes判别准则:错判损失最小或后验概率最大。
-
数据预处理:PCA前通常进行标准正态变换 (均值0,标准差1)。
-
因子负荷定义:实际上是变量 \(x_i\) 和因子 \(F_j\) 的相关系数。
-
特殊因子 \(\delta_i\):是指只影响一个观察变量的因子,且包含随机误差。
-
方法选择逻辑:
-
无标签分类 \(\rightarrow\) 聚类分析
-
有标签分类 \(\rightarrow\) 判别分析
-
单纯降维/综合指标 \(\rightarrow\) 主成分分析
-
问卷结构效度/潜在维度 \(\rightarrow\) 因子分析