第12章 多水平模型
1. 概述与适用场景
为什么需要多水平模型?
传统的线性回归模型(OLS)有一个重要的前提假设:观测个体之间相互独立。 但在实际医学与社会科学研究中,数据往往呈现层次结构 (Hierarchical Structure) 或 嵌套结构 (Nested Structure),导致个体间不独立:
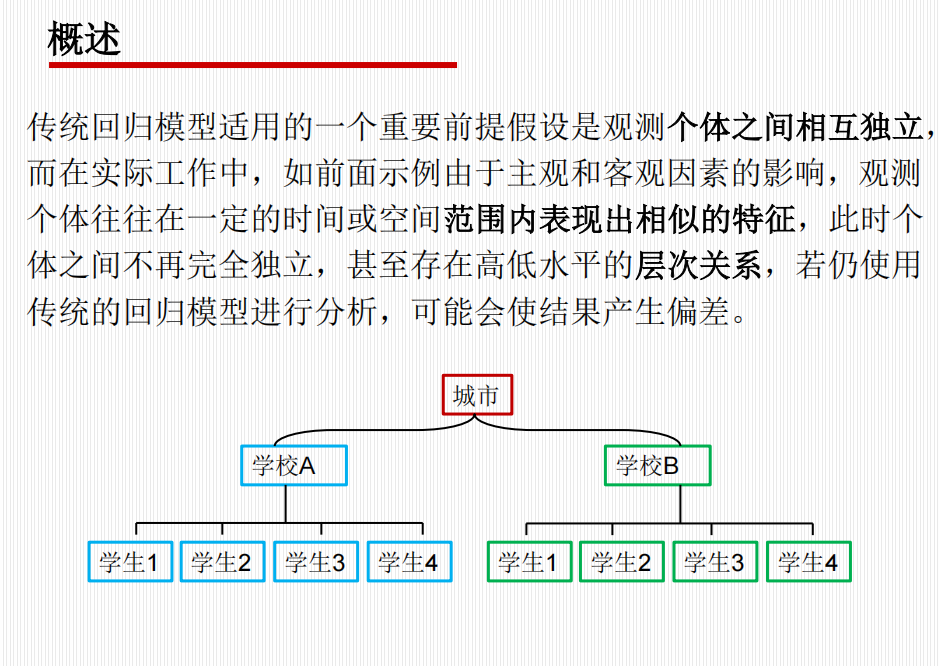
- 空间/组织嵌套:学生嵌套在班级中,班级嵌套在学校中;病人嵌套在医院中。
- 时间/重复测量嵌套:同一个体在不同时间点的多次测量(如儿童生长发育),由于源自同一人,数据具有相关性。
如果忽略这种层次结构,强行使用传统回归,会导致:
-
标准误 (Standard Error) 被错误低估。
-
统计推断失效(假阳性增加)。
-
辛普森悖论 (Simpson's Paradox):部分组别的趋势在合并后消失甚至反转。
数据结构定义
- 水平 1 (Level-1):低水平单位,如“个体”、“学生”、“孕产妇”。
- 水平 2 (Level-2):高水平单位,如“区县”、“班级”、“医院”。
例题:多水平模型的数据类型
多水平模型主要用于处理什么类型的数据?
A. 独立数据
B. 嵌套数据
C. 时间序列数据
D. 横截面数据
E. B和C均可
解析:多水平模型既适用于空间上的嵌套数据(如学生在班级),也适用于个体内部重复测量的时间序列数据(即重复测量资料)。选 E。
例题:层次结构的判定
在一个研究学生学业成绩的多水平模型中,以下哪个变量最适合作为第二水平 (Level-2) 的单位?
A. 学生的学习时间
B. 学生的性别
C. 学生所在的班级
D. 学生的期末考试分数
解析:Level-2 是容纳个体的容器(组别)。学习时间、性别、分数都是学生(Level-1)的特征,而班级是学生归属的组别。选 C。
2. 随机截距模型
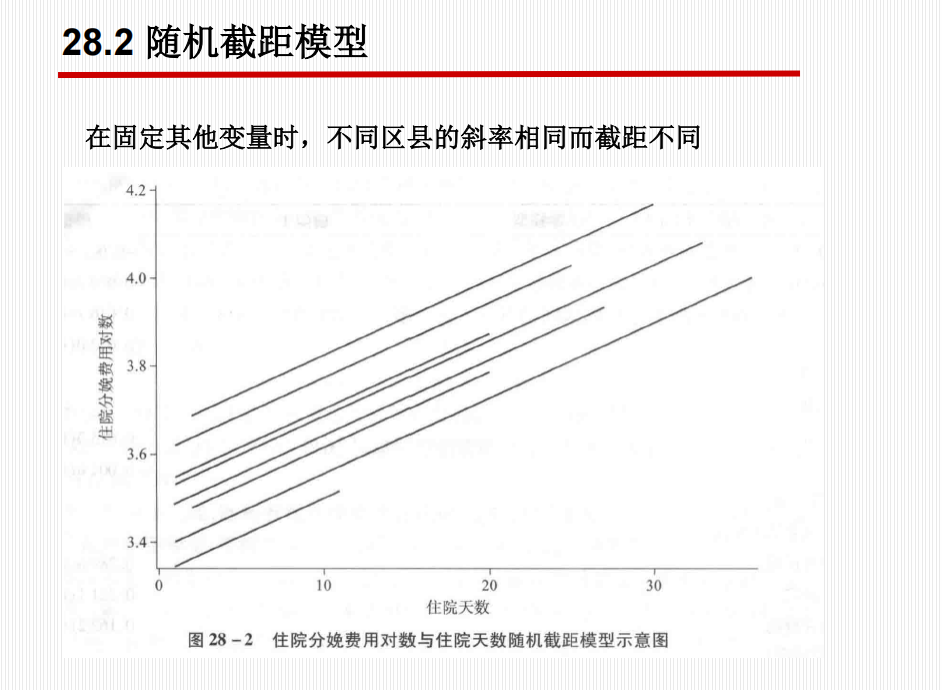
核心思想
假设不同组别(Level-2)的截距(Baseline)不同,但自变量对因变量的影响(斜率)在各组间是相同的(平行的)。即模型允许不同群体有自己的起点。
模型公式
-
零模型 (Null Model):不含任何自变量,仅用于拆分方差。 $$ y_{ij} = \beta_{0j} + e_{ij} $$
\[ \beta_{0j} = \beta_0 + u_{0j} \]合并后: $$ y_{ij} = \beta_0 + u_{0j} + e_{ij} $$
- \(y_{ij}\):第 \(j\) 个组中第 \(i\) 个个体的观测值。
- \(\beta_0\):固定截距(所有组的平均截距)。
- \(u_{0j}\):随机截距(第 \(j\) 个组的截距与平均截距的偏差),服从 \(N(0, \sigma^2_{u0})\)。
- \(e_{ij}\):残差(个体层面的误差),服从 \(N(0, \sigma^2_{e})\)。
组内相关系数 (ICC)
用于衡量组间差异占总变异的比例,判断是否有必要使用多水平模型。
- 含义:因变量的总变异中,可以由组间差异解释的比例,组间方差与总方差之比。
- 判断标准:
- \(ICC < 0.059\):组内相关性低,可考虑传统回归。
- \(ICC > 0.059\):组内相关性不可忽略,应使用多水平模型。
例题:ICC的含义
在多水平模型中,组内相关系数 (ICC) 反映了什么?
A. 因变量的总变异中可以由组间差异解释的比例
B. 自变量与因变量之间的相关程度
C. 模型中随机效应的显著性水平
D. 第一水平残差与第二水平残差的相关性
解析:ICC定义即为组间方差与总方差之比,反映了组间的异质性或组内的同质性。选 A。
例题:多水平模型的优势
与传统的普通最小二乘法 (OLS) 回归相比,多水平模型的主要优势在于?
A. 对样本量的要求更低
B. 计算过程更为简单快捷
C. 能更准确地处理嵌套数据中的非独立性问题
D. 对变量的分布假设更少
解析:OLS假设独立,而嵌套数据不独立。多水平模型正是为了解决这一非独立性问题。选 C。
假设检验
Wald检验
似然比检验
置信区间
加入自变量的随机截距模型
- \(\beta_1\) 是固定斜率:表示 \(x\) 每增加1单位,\(y\) 平均改变的量,这对所有组都是一样的。
- \(u_{0j}\) 使得不同组有不同的起始水平(截距)。
例题:随机截距模型的理解
关于随机截距模型,以下哪个表述是正确的?
A. 模型中所有预测变量的效应都随组别变化
B. 允许不同组别在因变量上有不同的基线水平,每个组的截距是来自一个分布的随机变量
C. 模型的截距对于所有组别都是固定的
D. 主要用于分析时间序列数据的趋势
解析:随机截距模型的核心就是“截距随机,斜率固定”。A描述的是随机斜率,C描述的是OLS固定效应。B准确描述了允许不同组别有不同基线(截距)。选 B。
3. 随机斜率模型
核心思想
不仅各组的截距不同,自变量对因变量的影响(斜率)在不同组别之间也是不同的。
- 例如:住院天数对费用的影响,在不同区县(有的区县医疗贵,有的便宜)可能增加的幅度不同。
模型公式
其中斜率也是随机的: \(\beta_{1j} = \beta_1 + u_{1j}\) 合并后得到混合模型方程: $$ y_{ij} = (\beta_0 + \beta_1 x_{ij}) + (u_{1j} x_{ij} + u_{0j} + e_{ij}) $$
- 固定部分:\(\beta_0 + \beta_1 x_{ij}\)(总体平均趋势)。
- 随机部分:\(u_{1j} x_{ij} + u_{0j} + e_{ij}\)(组特有的偏差)。
- \(u_{1j}\):第 \(j\) 个组的斜率与平均斜率 \(\beta_1\) 的差值。
模型的比较与选择
- 假设检验:检验随机斜率的方差 \(\sigma^2_{u1}\) 是否显著。如果不显著,说明各组斜率相同,应退回到随机截距模型。
- 比较指标:
- -2 对数似然值 (-2 Log Likelihood):值越小越好。
- 似然比检验 (LRT):计算 \(G = (-2LL_{model A}) - (-2LL_{model B})\),服从 \(\chi^2\) 分布。
- AIC / BIC:信息准则,越小越好。
例题:随机斜率的意义
一个研究不同疗法对病人康复效果的模型,将病人作为第一水平,医院作为第二水平。如果模型设定为随机斜率模型,这意味着什么?
A. 所有医院的病人都具有相同的初始康复水平
B. 不同疗法的效果在所有医院中是完全相同的
C. 病人的康复效果与疗法无关
D. 疗法的效果可能因医院而异
解析:随机斜率意味着自变量(疗法)的系数(效果)在不同组别(医院)间是变化的。选 D。
例题:斜率方差的解释
假设你正在研究员工满意度 (Y) 与工作自主权 (X) 的关系,数据来自多个不同的公司。你构建了一个随机截距和随机斜率模型。结果显示斜率的方差显著,这意味着?
A. 所有公司的员工都具有相同的平均满意度
B. 工作自主权对员工满意度的影响在不同公司间存在差异
C. 工作自主权不是一个显著的预测变量
D. 该模型不适合分析此数据
解析:斜率方差显著 \(\Rightarrow\) 斜率不是固定的 \(\Rightarrow\) X对Y的影响力在不同组间不同。选 B。
例题:模型比较
在比较一个仅包含随机截距的模型 (模型A) 和一个同时包含随机截距与随机斜率的模型 (模型B) 时,以下哪项通常不作为选择模型B优于模型A的直接依据?
A. 模型B的样本量更大
B. 模型B的-2对数似然值 (-2 Log Likelihood) 显著更小
C. 似然比检验 (LRT) 结果显著
D. 模型B的信息准则 (如AIC或BIC) 更低
解析:模型比较是在同一组数据上进行的,样本量(A)在两个模型中是一样的,不是比较依据。B、C、D都是标准的模型拟合优度评价指标。选 A。
4. 总结:三种模型的对比
| 特征 | 普通线性回归 (OLS) | 随机截距模型 | 随机斜率模型 |
|---|---|---|---|
| 截距 \(\beta_0\) | 固定 (所有组相同) | 随机 (各组有自己的截距) | 随机 (各组有自己的截距) |
| 斜率 \(\beta_1\) | 固定 (所有组相同) | 固定 (所有组平行) | 随机 (各组斜率不同) |
| 方差结构 | 仅考虑个体残差 | 分解为组间与组内方差 | 复杂的方差-协方差结构 |
| 适用性 | 独立数据 | 组间基线不同,效应相同 | 组间基线不同,效应也不同 |
| 图形示意 | 一条直线 | 一组平行线 | 一组相交线 (截距斜率均不同) |
跨级交互作用
在随机斜率模型中,可以进一步引入 Level-2 的变量来解释斜率为什么变化。 * 例如:在模型中纳入“住院天数 \(\times\) 区县类型”的交互项,查看区县类型(Level-2特征)是否修正了住院天数(Level-1自变量)对费用的影响。